2025.04.25 - [자격증] - 제 10회 빅데이터분석기사 필기 독학 합격후기 (교재 추천, 비전공자 공부법)
제 10회 빅데이터분석기사 필기 독학 합격후기 (교재 추천, 비전공자 공부법)
안녕하세요!제 10회 빅데이터분석기사 필기 (2025.04.05 시행) 합격 후기를 남겨보겠습니다.저는 난이도가 무난하다고 느껴졌고, 다른 수험자분들도 그렇게 느끼신 것 같습니다.보통 필기 합격률이
codingtoday.tistory.com
안녕하세요! 이번에 빅데이터분석기사를 취득했습니다.

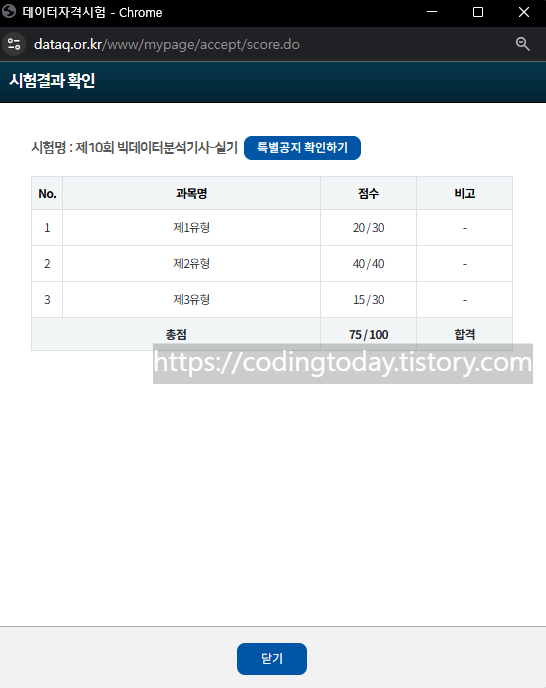
4월부터 연달아서 빅분기 필기 - ADsP - SQLD - 빅분기 실기를 준비했는데 다행히 모두 합격했습니다!
참고로 저는 컴퓨터공학 전공자입니다.
최대한 비전공자 입장에서 합격 팁을 세세하게 작성해보겠습니다.
10회차 난이도가 많이 쉬웠던 것 같아요. 100점인 분들이 많더라구요!!
일단 저는 책, 강의를 사지 않고 공부했다는 점 참고 부탁드립니다. 전공자분들은 충분히 독학으로 합격할 수 있을 것 같아요!
혼자 공부하기 힘들거나 시간이 많이 부족한 비전공자분들은 퇴근후딴짓님 강의, 데이터마님 강의가 유명한 것 같으니 두 개 비교해보시고 구매하시는 것 추천드립니다!
비전공자분들은 한달 ~ 두달 넉넉하게 기간을 잡고 공부하시는 걸 추천드려요!!
전공자분들, 파이썬 많이 써보신 분들은 일단 구름환경 문제나 기출문제 한 번 보시고,
0. 준비
일단 코드 편집기가 필요한데, VSCode, Jupyter 등 다 괜찮지만 뭘 설치하는 게 싫다.. 힘들다.. 하시는 분들은
코랩 추천드립니다! 회원가입 후 바로 이용할 수 있습니다.
colab.google
Colab is a hosted Jupyter Notebook service that requires no setup to use and provides free access to computing resources, including GPUs and TPUs. Colab is especially well suited to machine learning, data science, and education.
colab.google
1. 데이터마님
저는 데이터마님의 전처리 100 문제를 먼저 풀었습니다.
틀린 문제는 최대한 자주, 많이 반복해주시는 걸 추천드려요! (시험 치기 전까지 계속 반복)
https://www.datamanim.com/dataset/99_pandas/pandasMain.html
판다스 연습 튜토리얼 — DataManim
판다스 연습 튜토리얼 10회 빅분기 실기 대비 강의, 블로그만으로는 도저히 안되겠다ㅠ 하시는분들에게 추천합니다. 아 제발 광고 한번씩만 눌러주세요 ㅠㅠ 두번은 더 좋구요 오픈톡방 (pw: dbsca
www.datamanim.com
1유형, 2유형, 3유형 실전문제도 있는데 저는 퇴근후딴짓님꺼 먼저 풀다보니 시간이 부족해서... 못 풀었습니다..
그래도 퇴근후딴짓님 캐글 문제가 좀 더 시험문제랑 비슷한 것 같아서 먼저 퇴근후딴짓님꺼 다 푸시고, 데이터마님 문제로 넘어가시는 걸 추천드립니다.
데이터마님 문제는 더 난이도가 높은 것 같습니다.
그리고 직접 운영하시는 오픈채팅방도 있어요!
모르는 거 질문하면 다들 친절하게 답변해주시고 정보 공유 등 많이 도움 됐어요~!
https://open.kakao.com/o/gJl1ud2c
빅데이터분석기사 ADP 실기 정보공유방
#밀도기반군집분석소문자로#풀방시2번방도있으니검색#빅데이터분석기사#adp#실기#실기대비#빅데이터분석기사#파이썬#adp파이썬#sqlp#dap
open.kakao.com
2. 퇴근후딴짓
데이터마님 전처리 100 문제를 푼 다음, 실전 문제로 넘어갔습니다.
https://www.kaggle.com/datasets/agileteam/bigdatacertificationkr/data
Big Data Certification KR
퇴근후딴짓 의 빅데이터 분석기사 실기 (Python, R tutorial code) 커뮤니티
www.kaggle.com
작업형1, 작업형2, 작업형3 예상문제가 많이 있는데 일단 저는 작업형2 문제만 다 풀었고 작업형3 문제는 중요한 부분만 임의로 뽑아서 연습했어요.
간단하게 몇 개만 정리했는데.. 혹시나 벼락치기하실 분들을 위해서 제가 정리한 pdf 올립니다!
3. 2유형 치트키 랜덤포레스트
2유형은 랜덤포레스트만 외우고 가면 만점 받을 수 있다고 봅니다. (10회차까지는 그랬음)
다른 합격자분들의 후기를 보면 대부분 전처리를 따로 하지 않고도 랜덤 포레스트만으로 2유형은 40점 만점을 받으신 분들이 많더라구요!! 오히려 전처리 하신 분들이 점수가 깎인 경우가 많았어요..
저도 랜덤포레스트만 외우고 갔습니다!!!
회귀 / 분류인지만 구분하고 사용하시면 돼요!
회귀는 예측대상이 숫자이고, 보통 평가지표가 RMSE, MSE, MAE입니다.
분류는 예측대상이 카테고리(이산형)이고 평가지표가 정확도, ROC-AUC, F1 Score, Recall, Precision 등입니다.
그리고 ROC-AUC 평가지표 사용 시에는 무조건 predict_proba(test)[:, 1]을 사용하셔야해요!!
제가 외운 코드입니다. 저는 파이썬 언어를 사용했고, R언어 관련 자료는 파이썬 보다 적은 것 같으니 처음 시작하시는 분들은 웬만하면 파이썬 추천드려요!!
(2025. 07. 04일자 구름 체험환경 2유형)
# 출력을 원하실 경우 print() 함수 활용
# 예시) print(df.head())
# getcwd(), chdir() 등 작업 폴더 설정 불필요
# 파일 경로 상 내부 드라이브 경로(C: 등) 접근 불가
import pandas as pd
train = pd.read_csv("data/customer_train.csv")
test = pd.read_csv("data/customer_test.csv")
# 사용자 코딩
pd.set_option("display.max_columns", None)
# 1. import 및 데이터 불러오기
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.preprocessing import LabelEncoder
import xgboost # 혹시나 랜덤포레스트 안될 경우 대비(근데 그럴 일은 거의 음)
# 2. EDA #HIDI
# print(train.head())
# print(train.info())
# print(train.isnull().sum()) # 환불금액 2300개
# print(train.describe())
# print(test.isnull().sum()) # 환불금액 1615개
# 3. 전처리(데이터 concat, pop, id drop, fillna, 범주형데이터 처리 - 원핫인코딩 또는 라벨인코딩)
y = train.pop('총구매액')
x_full = pd.concat([train, test], axis=0)
# print(x_full.info())
# x_full = x_full.drop(['회원ID'])
x_full['환불금액'] = x_full['환불금액'].fillna(0)
x_full = pd.get_dummies(x_full) # 원핫인코딩
# print(x_full.info())
# 4. 데이터 다시 분리 & train_test_split
x_train = x_full[:train.shape[0]]
x_test = x_full[train.shape[0]:]
# print(x_test.shape)
x_tr, x_val, y_tr, y_val = train_test_split(x_train, y, test_size=0.2)
# print(x_tr.shape, x_val.shape, y_tr.shape, y_val.shape)
# 5. 모델 생성, 학습
model = RandomForestRegressor(random_state=42)
model.fit(x_tr, y_tr)
y_val_pred = model.predict(x_val)
# 6. 검증
rmse_val = root_mean_squared_error(y_val, y_val_pred)
r2_val = r2_score(y_val, y_val_pred)
# print("검증:", rmse_val, r2_val) #785.6299, #0.7683
# 7. 제출
pred = model.predict(x_test)
output = pd.DataFrame({'pred': pred})
output.to_csv("result.csv", index=False)
result = pd.read_csv("result.csv")
print(result)
# 답안 제출 참고
# 아래 코드는 예시이며 변수명 등 개인별로 변경하여 활용
# pd.DataFrame변수.to_csv("result.csv", index=False)
그리고 저는 train_test_split 사용해서 검증을 수행했는데, 대부분 데이터의 크기가 그렇게 크지 않아서 수행하는 게 좋지 않을 수도 있다고 하더라구요.. 그래서 저는 검증한 후에 다시 x_trian, x_test만 사용해서 학습하고 예측 후 제출했습니다! 참고해주세요!! (사실상 시간 없으신 분들.. 최대의 가성비와 효율을 원하신다면 검증 과정 빼셔도 됩니다.)
그치만 read_csv 활용해서 정답 예시 행 개수랑 본인이 제출한 데이터 행 개수가 맞는지는 꼭 확인하시길 바랍니다!
4. 구름 시험환경
dataq에서 실제 빅데이터분석기사 실기 시험을 칠 때 사용되는 시험 환경을 제공해줍니다.
여기서 충분히 연습해보시고, 올라와있는 연습문제도 다 풀 수 있는 정도로 연습하시길 추천드립니다.
실기 체험환경 문제 답은 보통 유튜브에 강의로도 많이 올라와있으니 참고하시면 됩니다!!
https://dataq.goorm.io/exam/3/%EC%B2%B4%ED%97%98%ED%95%98%EA%B8%B0/quiz/1
구름EDU - 모두를 위한 맞춤형 IT교육
구름EDU는 모두를 위한 맞춤형 IT교육 플랫폼입니다. 개인/학교/기업 및 기관 별 최적화된 IT교육 솔루션을 경험해보세요. 기초부터 실무 프로그래밍 교육, 전국 초중고/대학교 온라인 강의, 기업/
edu.goorm.io
5. 기출문제
보통 블로그, 카페, 유튜브에 기출문제가 많이 올라와있는데 찾아보시면 됩니다!!
저는 홍쌤 사이트에서 기출 다운로드 받아서 풀었습니다! (그때는 무료였는데 지금은 모르겠어요..)
저는 시간이 없어서 9, 8회만 풀었는데 최대한 많이 푸시는 걸 추천드릴게요!!
에이치데이터랩
ALL CONTENTS 에이치데이터랩의 모든 콘텐츠를 소개합니다.
hdatalab.co.kr
6. 정리 & 팁
저는 노션에 헷갈리는 부분, 중요한 부분 정리하면서 공부했는데 도움이 많이 됐습니다!
블로그든 노션이든 좋으니 보기 편한 곳에 정리하시는 걸 추천드려요!!
그리고 시험환경에서 체크할 부분이 있는데 아래 영상 참고하시면 좋을 것 같습니다~!!
https://youtu.be/ucKYrlbTN2s?si=cq7aL9z38P1lvNla
!팁
1. 데이터가 너무 크면 출력하면 잘 안보일 수가 있습니다. pd.set_option(’display.max_columns’, None) 으로 설정해두고 코딩 시작하시길 추천드려요!!
2. 시험장에서 갑자기 함수이름이 생각이 안난다.. 하시면 -> dir(df) 활용해서 찾을 수 있습니다.
3. 함수 사용명이 생각 안나시면 help(함수명) 사용하면 확인하실 수 있습니다!!
연습할 때도 dir, help 많이 사용하시고 익히는 걸 추천드릴게요!
다들 합격하시길 바랍니다~!!
'자격증' 카테고리의 다른 글
| 2026 이기적 정보처리기사 필기 기본서 리뷰 (0) | 2026.01.11 |
|---|---|
| 2026 이기적 정보보안기사 필기+실기 올인원 책 리뷰 (1) | 2025.12.10 |
| 제 57회 SQL 개발자(SQLD) 개념서 X 일주일 독학 합격 후기 (비전공자 공부법, 노랭이) (1) | 2025.06.26 |
| 제45회 ADSP(데이터분석 준전문가) 복원 문제 (5) | 2025.06.05 |
| 제45회 ADsP(데이터 분석 준전문가) 독학 합격후기 (교재 추천, 비전공자 공부법) (7) | 2025.06.05 |